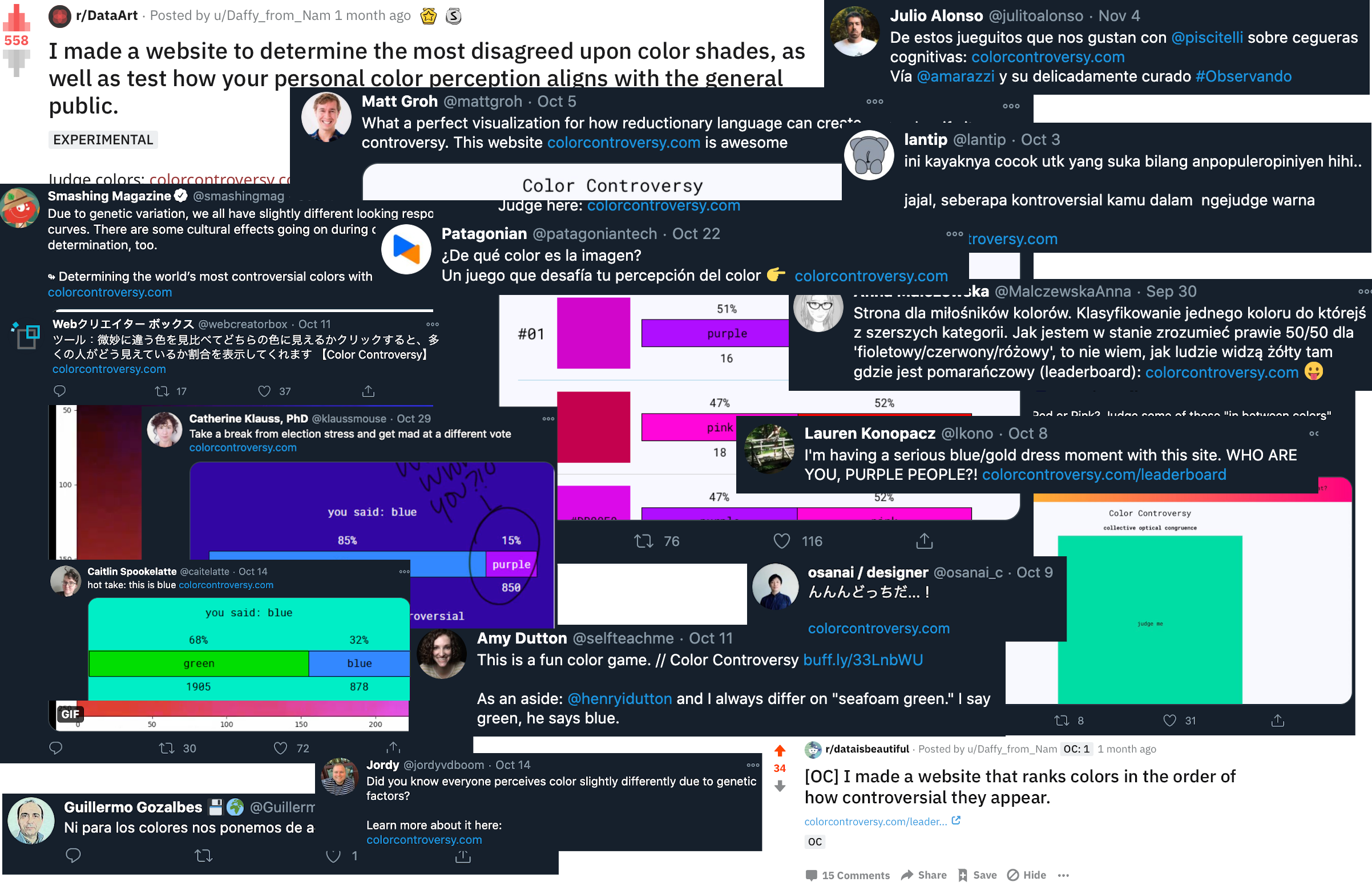
About 6 weeks ago, I launched colorcontroversy.com. Since then, the site has collected over 800,000 color judgements and been shared around the web more than I expected.
A much-simplified version of Randal Monroe of XKCD’s color survey, the site shows you a color shade and presents two color choices for that shade. For example, it shows you a dark turquoise and asks you if it’s Green or Blue. Then it shows you what other people thought it was.
This the first thing I’ve put out there that I wanted lots of random people to use and enjoy. I learned a lot from building it, some of which is discussed below.
don’t design in html/css#
Unless you’re Lynn Fisher, it can be pretty difficult to translate designs from your head immediately into code. This is obvious to any designer or artistic person, but these things I am not.
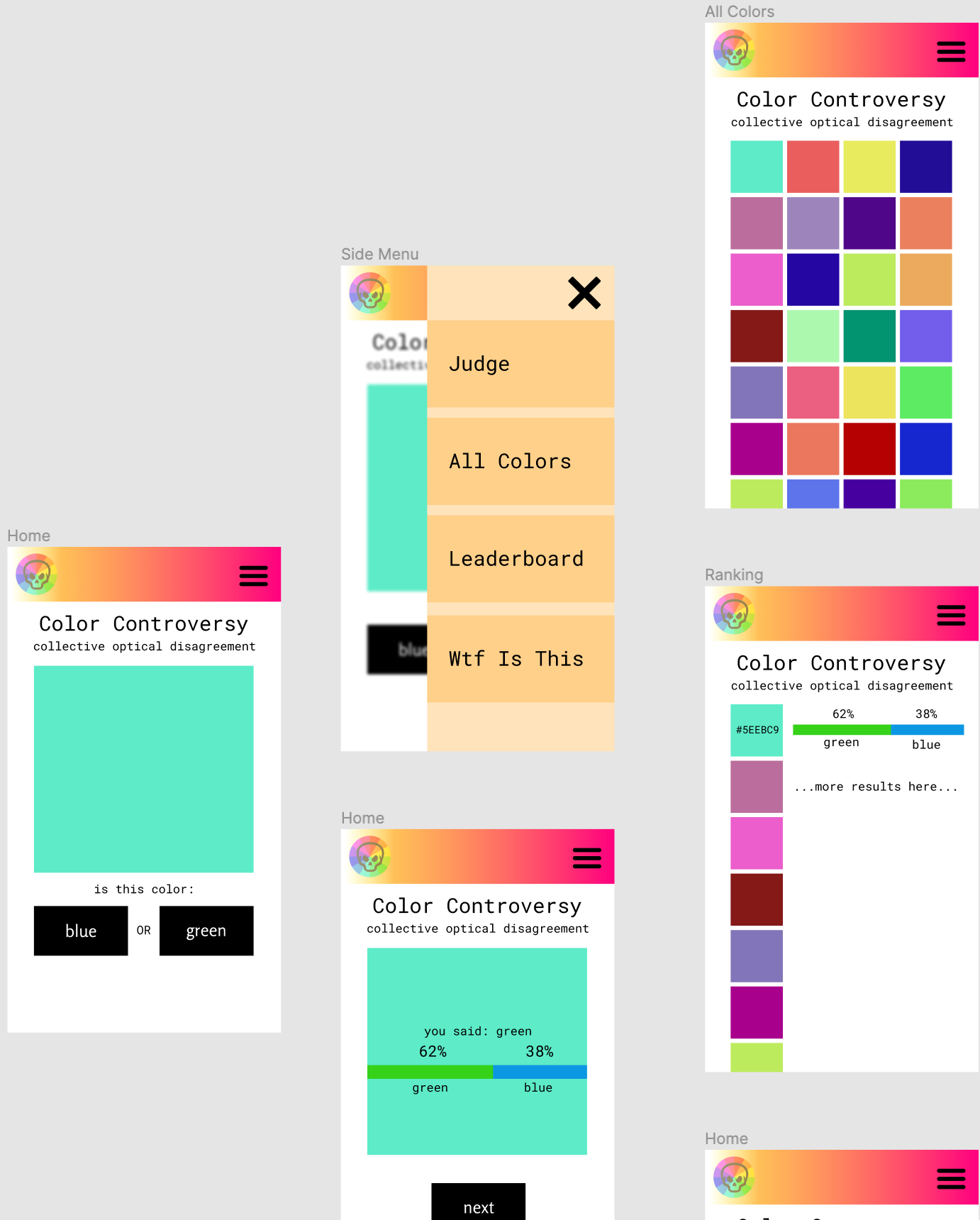
Turns out clicking and dragging is a lot easier than CSS when in ideation. The mocks were mostly done before I wrote a line of code. I was able to get feedback from friends on a real-looking site without any serious up-front investment.
sign up isn’t just for data collection#
The things that take my breath away on the internet almost always load and immerse quickly. A fluid simulation or a peaceful meditation - no sign up flow, no pop ups or ads, no cookie consent required, nothing between you and the experience.
Notably, the examples above deliver the entire content to the users’ browser up front, then no further interaction with the internet is required.
Color Controversy does not behave this way. It collects repeated user input and persists it in a far-away server. So what if someone wants to spam the site with repeated requests from an automated script? What if someone wants to DDoS the site just for the LuLz?
A h4ck3r would have nothing to gain from doing this, but I felt I should operate in the “whatever users can do, they will do” mindset. I could have embedded a unique token in the browser that the user would automatically include in their data submission when operating the site as intended, but how to obtain the token in a way some script couldn’t reproduce fairly easily?
When it comes down to it, deterrence for malicious action is limited without user-specific identification, i.e. sign up and login. Turns out there’s more to sign up than just pernicious data collection for profit!
Sign up and login were a deal breaker for me user-experience wise, so what I settled for was implementing server-side periodic backups of the database with the knowledge that I could at least restore the data to a valid state if someone did decide to mess with it. Luckily, this hasn’t been necessary so far.
done is better than perfect#
Could I have worked harder to figure out how to get the play-swagger plugin to parse my Enum color values so I wouldn’t have to replicate them manually on the frontend? Yes.
Is the color label text sometimes a little cut off on color labels on the results chart when the color is medium-controversial? Yes.
Are two different docker-compose files, one for dev and one for prod, the best way to do something resembling dev ops? Could I have pushed my built images to remote storage to avoid rebuilding them locally every time? Could I have figured out how to get my Scala Play container to compile and run on less RAM and saved a few dollars a month on AWS costs? Yes, yes, and yes.
But it’s done! It works! People use it, and no one has submitted angry github issues denigrating my intelligence. In fact, I got my first 3 github stars on the project! I love it as is and am ready to move on.
design data collection early#
I did something really smart and/or really dumb in designing the data model for Color Controversy.
I decided that the database would never grow past its original number of rows - color submissions simply trigger a SQL query that mutates one of the values in the row of that color:
UPDATE color
SET n_first = CASE WHEN (color.hex = '${hexColor}' AND color.first_option = '${choice}') THEN n_first + 1 ELSE n_first END
, n_second = CASE WHEN (color.hex = '${hexColor}' AND color.second_option = '${choice}') THEN n_second + 1 ELSE n_second END
I know Postgres will handle this atomically and liked the idea of a database that was basically the same size no matter how large the traffic grew. No indexing or normalization required when you only have ~100 rows of data 😎.
Unfortunately, someone online pointed out soon after launch that it would have made for some interesting data to collect a little more than just color judgements. Browser usage, mobile/tablet/desktop, general location and time of day along with judgement made makes for some interesting data analysis after the fact.
Fortunately, completely by accident, I can pretty much parse all this out of the Nginx logs, which I started backing up periodically soon after I realized my mistake. They are sitting around ready for me to sift through at some future time.
Unfortunately, now I’m sort of treating logs like a read-only database, and I maybe could have just designed this in to my Postgres schema in the first place without taking much of a performance hit. You win some, you lose some.
put your stuff out there#
The internet is cool and building dumb stuff is fun. Making for the web is also kind of terrifying, because it’s probably going to be around for a long time. Once you unleash it, it’s out there, ready for judgement and criticism. Write my name on it and people’s negative reaction to it could be thinly veiled negative reactions to MeAndMyStupidDumbBrainWhyWouldIEvenTryToMakeAThingAnywayGahhhhhhh.
I remember eagerly refreshing my first reddit submission for the site and it being downvoted to 0.
Then someone with a million twitter followers tweets it and getting 200k color judgements in a day.
Then I read harsh criticism of it on a french speaking early 2000’s-looking forum.
Then a niche Italian art blog emails me asking for permission to write about it for an article.
Then I watch as no one engages with it at all for 10 sequential hours.
Then John Austin, whose color theory talk I reference in the What? section of the site, tells me the site reached him before I could tweet at him about it.
Wild ride, I’ll tell ya!
in colorclusion#
It was fun and worth it and I’ll do it all again with something new! I may make a follow-up post at some point in the future once I parse through all the logs and make something pretty with them.