I wrapped up Nand2Tetris project 6 and completed project 7 this week. One satisfying thing about this course has been consistently connecting the “simple” implementations that the course outlines to the hyper complex implementations in the real world.
Project 7 outlined the idea of multi-stage compilation. Take a high level language and compile it to a “Virtual Machine Code”, with readable but lower level syntax. This “intermediate representation” can then be compiled further through assembly to machine code (the 1s and 0s) for a specific hardware platform (e.g. MacOS x86-64). Writing a compiler that does things in a few steps like this (high level programming language -> VM code -> assembly -> machine code) allows parts of the compiler to stay the same across hardware platforms!
For example, there is some program written in Rust. The rustc compiler will take it through multiple compilation steps (more than the simplified version outlined by nand2tetris above), only the lower levels of which deal with the specifics of the hardware platform. On the way to machine code, Rust compiles to LLVM IR (low-level virtual machine intermediate representation), which is analogous to the VM code outlined in nand2tetris.
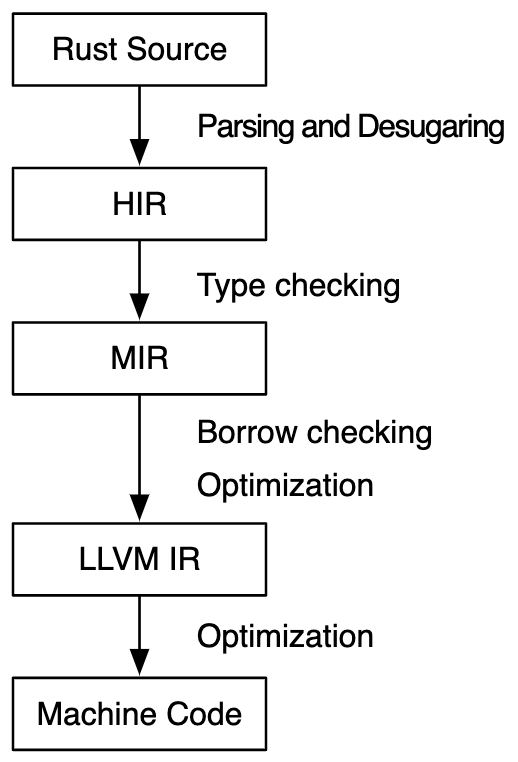
Facilitated by this multi-step approach, cross compilation is supported, where code is compiled for a hardware platform different than the one the compiler runs on.
Project 7 and 8 involve writing the VM code translator (VM code -> assembly for the hack computer). I wrote it in Rust. So my VM code translator is itself compiled in to an analogous intermediate representation before becoming machine code on my Mac. This compiled Rust program is then used to translate another intermediate representation (VM code) to assembly for a non-physical hardware platform (hack)! Wild stuff.
Other than Nand2Tetris, I continued with interview prep stuff, implementing linked lists, tries, and hash tables from scratch and grinding away at Leetcode style problems. I feel very conflicted by the whole software interview process. Interviewing at Tesla, I was asked highly specific questions about mechanical design (what are the considerations in designing this bolted joint, estimate the pressure in a scuba diver’s tank, etc.). I did quite well at these since I took MechE for 5 years in school. But i the end, I did no Mechanical Design during my 2 years at Tesla, primarily contributing through applications of software and data. Similarly, algorithm and system design questions may not be the best indicator of my future job performance. Nonetheless, it’s part of the game, and I’ll continue the grind, learning along the way!
I would highly recommend this explorable explanation of python dictionaries. Not only does it give a great picture at what python is actually doing under the hood for its dict built in data structure, but it teaches hash tables, collision resolution, and a number of interesting other concepts in four digestable chapters. This sort of teaching resource is so impressive and effective.